Niels Nübel
Frontend & Backend Developer
aus Hamburg
Joomla seit 2009
erster Joomla!Day 2011 in Hamburg
seit Juni 2018 Kicktemp
Kurz nur mir ich heiße Niels Nübel bin Frontend und Backend Developer aus Hamburg und habe mit Joomla angefangen im Jahr 2009.
Themen
Warum Git?
Grundlegende Konzepte
Warum Git?
April 2005
Linus Torvalds
Git hat eine rasante Erfolgsgeschichte hinter sich. Im April 2005 begann
Linus Torvalds, Git zu implementieren, weil er keinen Gefallen an den
damals verfügbaren Open-Source-Versionsverwaltungen fand. Heute,
im Herbst 2016, liefert Google Millionen von Suchtreffern, wenn man
nach »git version control« sucht. Für neue Open-Source-Projekte ist es
zum Standard geworden, und viele große Open-Source-Projekte sind zu
Git migriert.
Warum Git?
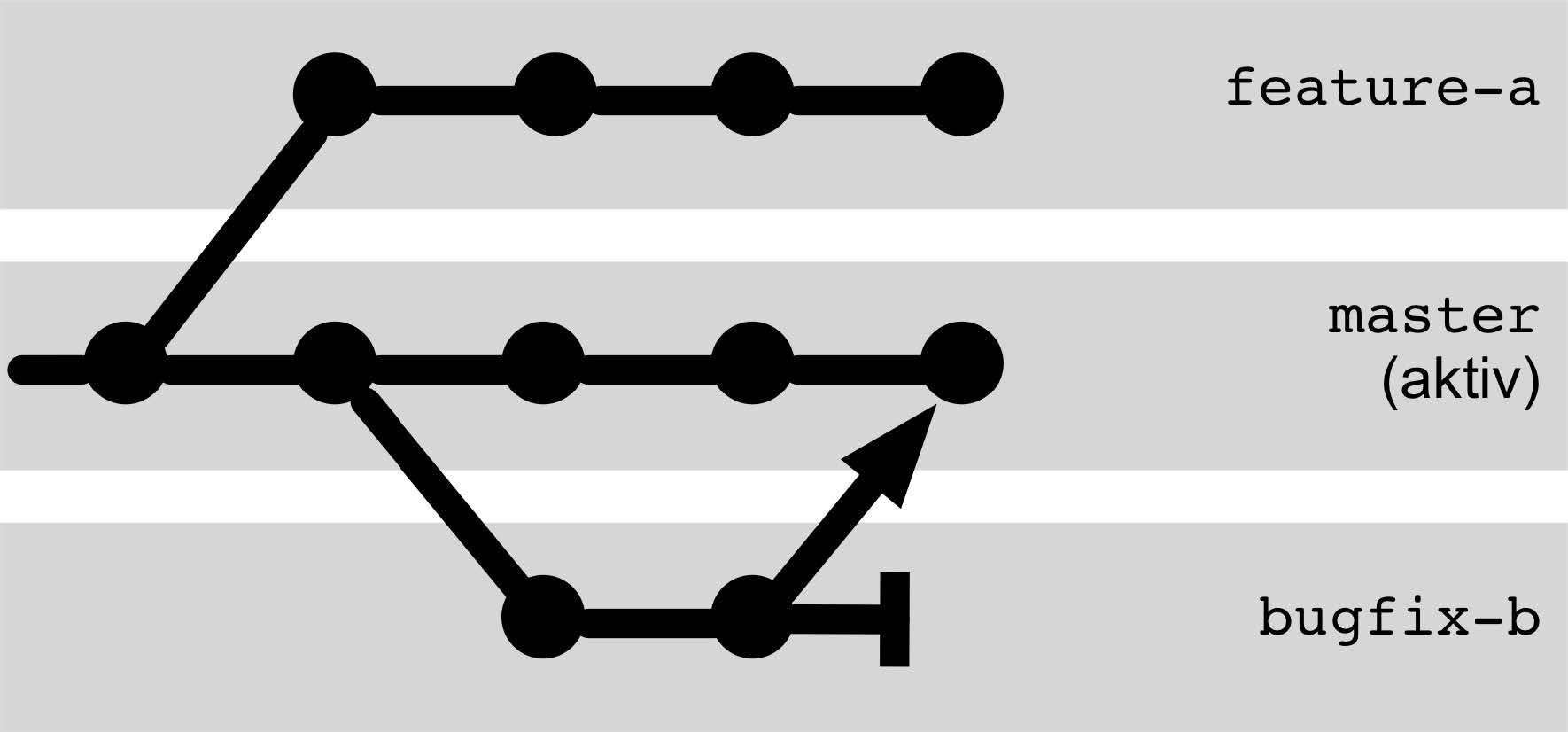
Arbeiten mit Branches
Flexibilität in den Workflows
Contribution
Nachvollziehbare Herkunft von Sourcecode
Performance
Robust gegen Fehler und Angriffe
Offline- und Multisite-Entwicklung
Administrierbarkeit
Starke Open-Source-Community
Erweiterbarkeit
Arbeiten mit Branches: Wenn viele Entwickler gemeinsam an einer
Software arbeiten, entstehen parallele Entwicklungsstränge, die immer
wieder auseinanderlaufen und zusammengeführt werden müssen.
Genau dafür ist Git entwickelt worden. Es bietet daher umfassende
Unterstützung zum Branchen, Mergen, Rebasen und Cherry-
Picken.
Flexibilität in den Workflows: Manche sagen, dass Git im Grunde gar
keine Versionsverwaltung sei, sondern ein Baukasten, aus dem sich
jeder seine eigene Versionsverwaltung zusammensetzen kann. Git
ist außergewöhnlich flexibel. Ein einzelner Entwickler kann es für
sich allein nutzen, agile Teams finden leichtgewichtige Arbeitsweisen
damit, aber auch große internationale Projekte mit zahlreichen
Entwicklern an mehreren Standorten können passende Workflows
entwickeln.
Contribution: Die meisten Open-Source-Projekte existieren durch freiwillige
Beiträge von Entwicklern. Es ist wichtig, das Beitragen so
einfach wie nur möglich zu machen. Bei zentralen Versionsverwaltungen
wird dies oft erschwert, weil man nicht jedem schreibenden
Zugriff auf das Repository geben möchte. Jeder kann ein Git-
Repository klonen, damit vollwertig arbeiten und dann später die
Änderungen weitergeben (»Mit Forks entwickeln« (Seite 163)).
Nachvollziehbare Herkunft von Sourcecode: Die Entwickler von Git
haben es als Content Tracker bezeichnet. Damit meinen sie ein
Werkzeug, das die Herkunft von Inhalten, insbesondere Source
code, aufzeigen kann. Git kann dies selbst dann, wenn Code zusammengeführt
wurde (Merge) oder Dateien verschoben und umbenannt
wurden. Sogar kopierte Codeabschnitte können erkannt
und zugeordnet werden.
Performance: Auch bei Projekten mit vielen Dateien und langen Historien
bleibt Git schnell. In weniger als einer halben Minute wechselt
es zum Beispiel von der aktuellen Version auf eine sechs Jahre
ältere Version der Linux-Kernel-Sourcen – auf einem kleinen
MacBook Air. Das kann sich sehen lassen, wenn man bedenkt,
dass über 200.000 Commits und 40.000 veränderte Dateien dazwischenliegen.
Robust gegen Fehler und Angriffe: Da die Historie auf viele dezentrale
Repositorys verteilt wird, ist ein schwerwiegender Datenverlust
unwahrscheinlich. Eine genial simple Datenstruktur im Repository
sorgt dafür, dass die Daten auch in ferner Zukunft interpretierbar
bleiben. Der durchgängige Einsatz kryptografischer Prüfsummen
erschwert es Angreifern, Repositorys unbemerkt zu korrumpieren.
Offline- und Multisite-Entwicklung: Die dezentrale Architektur macht
es leicht, offline zu entwickeln, etwa unterwegs mit dem Laptop.
Bei der Entwicklung an mehreren Standorten ist weder ein zentraler
Server noch eine dauerhafte Netzwerkverbindung erforderlich.
Administrierbarkeit: Git ist einfach zu betreiben und zu administrieren.
Alle Daten und Konfigurationen werden in einfachen Dateien
gespeichert. Für Backups oder Umzüge genügen die Standardtools
des Betriebssystems. Es muss kein Git-spezifischer Dienst eingerichtet
werden. Alle Operationen werden durch Kommandozeilenbefehle
bereitgestellt. Repositorys werden meist über SSH oder HTTP
zugänglich gemacht, sodass man die Authentifizierung und Autorisierung
des Betriebssystems bzw. Webservers nutzen kann. Zahlreiche
mächtige Befehle erlauben es, das Repository zu manipulieren.
Die dezentrale Natur von Git macht es leicht, Änderungen zuerst
an einem Klon zu erproben, bevor man sie öffentlich macht.
Starke Open-Source-Community: Neben der detaillierten offiziellen
Dokumentation unterstützen zahlreiche Anleitungen, Foren, Wikis
etc. den Anwender. Es existiert ein Ökosystem aus Tools, Hosting-
Plattformen, Publikationen, Dienstleistern und Plug-ins für Entwicklungsumgebungen,
und es wächst stark.
Erweiterbarkeit: Git bietet neben komfortablen Befehlen für den Anwender
auch elementare Befehle, die einen direkteren Zugang zum
Repository erlauben. Dies macht Git sehr flexibel und ermöglicht
individuelle Anwendungen, die über das hinausgehen, was Git von
Haus aus bietet.
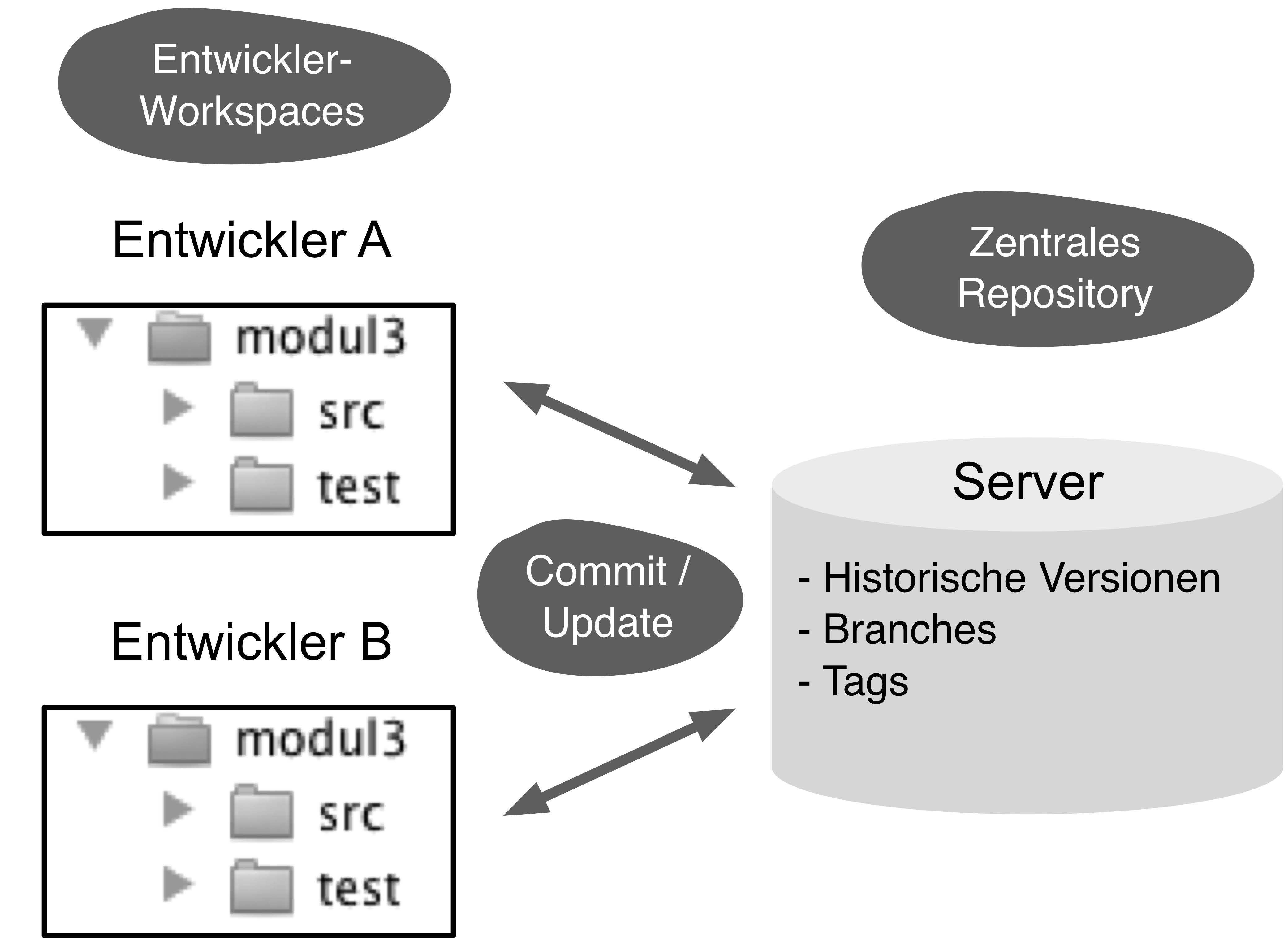
Zentrale Versionsverwaltung
zeigt die typische Aufteilung einer zentralen Versionsverwaltung,
z. B. von CVS oder Subversion. Jeder Entwickler hat auf
seinem Rechner ein Arbeitsverzeichnis (Workspace) mit allen Projektdateien.
Diese bearbeitet er und schickt die Änderungen regelmäßig per
Commit an den zentralen Server. Per Update holt er die Änderungen der anderen Entwickler ab. Der zentrale Server speichert die aktuellen
und historischen Versionen der Dateien (Repository). Parallele Entwicklungsstränge
(Branches) und benannte Versionen (Tags) werden
auch zentral verwaltet.
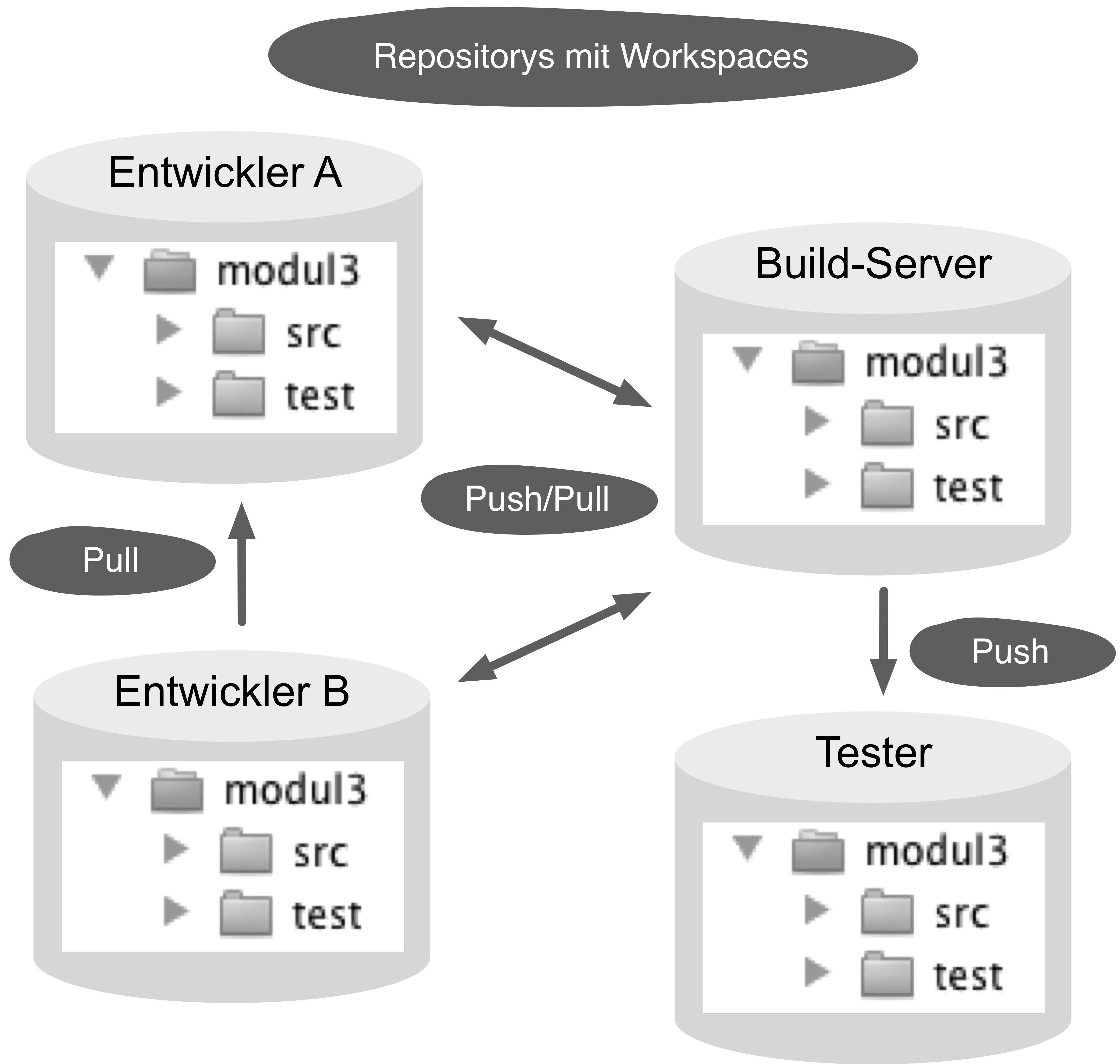
Dezentrale Versionsverwaltung
zeigt die typische Aufteilung einer zentralen Versionsverwaltung,
z. B. von CVS oder Subversion. Jeder Entwickler hat auf
seinem Rechner ein Arbeitsverzeichnis (Workspace) mit allen Projektdateien.
Diese bearbeitet er und schickt die Änderungen regelmäßig per
Commit an den zentralen Server. Per Update holt er die Änderungen der anderen Entwickler ab. Der zentrale Server speichert die aktuellen
und historischen Versionen der Dateien (Repository). Parallele Entwicklungsstränge
(Branches) und benannte Versionen (Tags) werden
auch zentral verwaltet.
Repository Arten
Blessed
Shared
Workflow
Fork
Blessed Repository: Aus Ein Projekt aufsetzen diesem Repository werden die »offiziellen« Releases erstellt.
Shared Repository: Dieses Repository dient dem Austausch zwischen den Entwicklern im Team. In kleinen Projekten kann hierzu auch das Blessed Repository genutzt werden. Bei einer Multisite-Entwicklung kann es auch mehrere geben.
Workflow Repository: Ein solches Repository wird nur mit Änderungen befüllt, die einen bestimmten Status im Workflow erreicht haben, z. B. nach erfolgreichem Review.
Fork Repository: Dieses Repository dient der Entkopplung von der Entwicklungshauptlinie (zum Beispiel für große Umbauten, die nicht in den normalen Release-Zyklus passen) oder für experimentelle
Entwicklungen, die vielleicht nie in den Hauptstrang einfließen
sollen.
Vorteile
Hohe Performance
Effiziente Arbeitsweisen
Offline-Fähigkeit
Flexibilität der Entwicklungsprozesse
Backup
Wartbarkeit
Hohe Performance: Fast alle Operationen werden ohne Netzwerkzugriff
lokal durchgeführt.
Effiziente Arbeitsweisen: Entwickler können lokale Branches benutzen,
um schnell zwischen verschiedenen Aufgaben zu wechseln.
Offline-Fähigkeit: Entwickler können ohne Serververbindung Commits
durchführen, Branches anlegen, Versionen taggen etc. und diese
erst später übertragen.
Flexibilität der Entwicklungsprozesse: In Teams und Unternehmen
können spezielle Repositorys angelegt werden, um mit anderen Abteilungen,
z. B. den Testern, zu kommunizieren. Änderungen werden
einfach durch ein Push in dieses Repository freigegeben.
Backup: Jeder Entwickler hat eine Kopie des Repositorys mit einer
vollständigen Historie. Somit ist die Wahrscheinlichkeit minimal,
durch einen Serverausfall Daten zu verlieren.
Wartbarkeit: Knifflige Umstrukturierungen kann man zunächst auf einer
Kopie des Repositorys erproben, bevor man sie in das Original-
Repository überträgt.
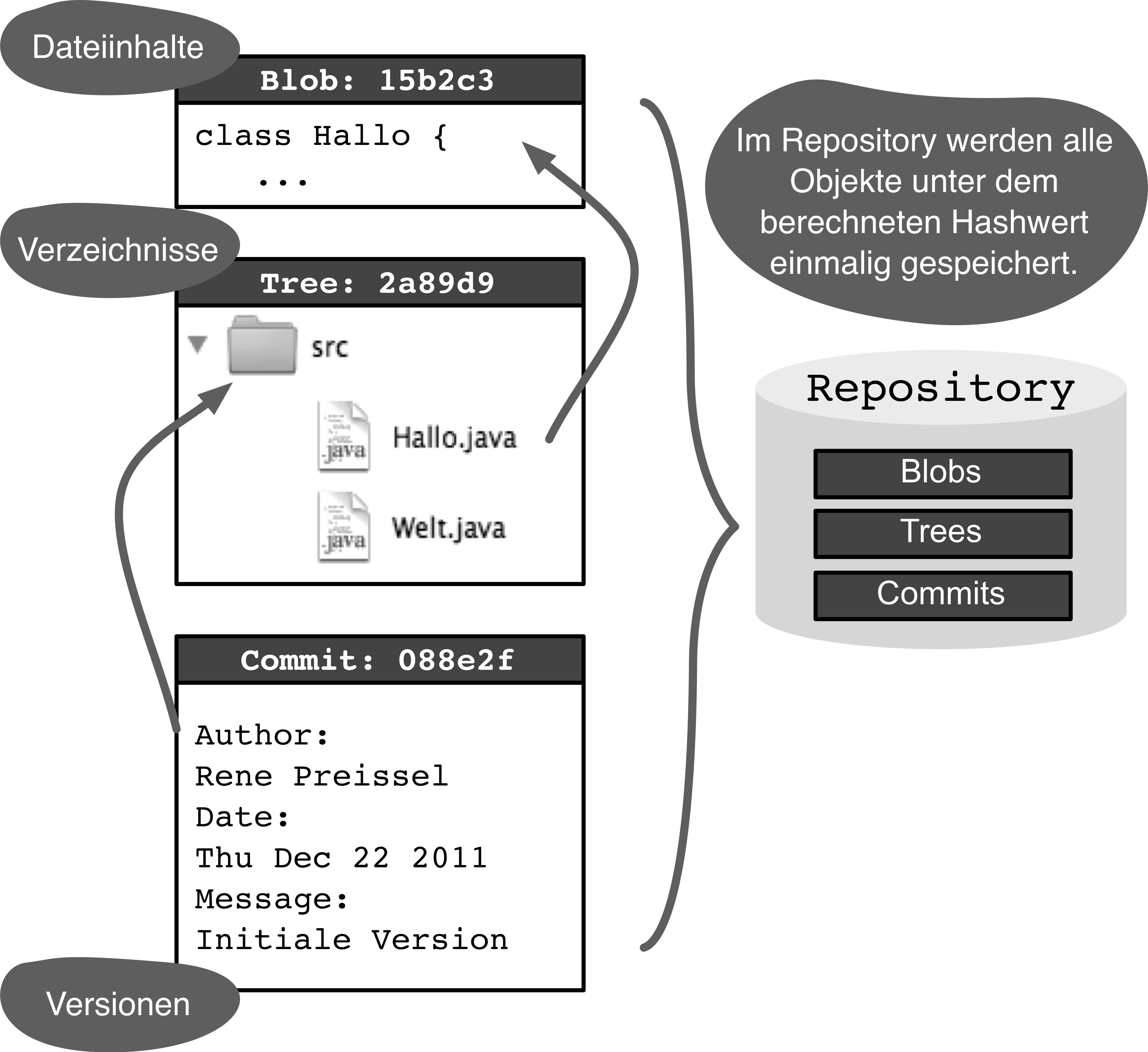
Das Repository
die Grundlage dezentralen Arbeitens
Das Repository ist im Kern ein effizienter Datenspeicher. Im Wesentlichen enthält es:
Inhalte von Dateien (Blobs)
Verzeichnisse (Trees)
Versionen (Commits)
Das Repository
hexadezimaler Hashwert
1632acb65b01c6b621d6e1105205773931bb1a41.
Diese Hashwerte dienen als Referenz
zwischen den Objekten und als Schlüssel, um die Daten später
wiederzufinden
Vorteile Hashwert
Hohe Performance
Redundanzfreie Speicherung
Dezentrale Versionsnummern
Effizienter Abgleich zwischen Repositorys
Integrität der Daten
Automatische Erkennung von Umbenennungen
Branching und Merging
Verzweigen (Branching)
Branches entstehen durch paralleles Arbeiten.
Zusammenzuführen (Merging)
ungeplante Verzweigung
Explizite Branches
Windows-User
Git-Bash
> git com< TAB>
> git commit
> git c< TAB>< TAB>
checkout cherry cherry-pick citool
clean clone commit config
> git commit --a< TAB>< TAB>
--all --amend --author=
Git einrichten
> git config --global user.name hmustermann
> git config --global user.email "hans@mustermann.de"
Lieblingstexteditor
> git config --global core.editor vim # VI improved
> git config --global core.editor "atom --wait" # Atom editor
> git config --global core.editor notepad # Windows notepad
Unser erstes Projekt
mkdir gitprojekte
cd gitprojekte
mkdir erste-Schritte
cd erste-Schritte
touch bar.txt
touch foo.txt
Ergebnis
gitprojekte
└── erste-schritte
├── bar.txt
└── foo.txt
Unser erstes Repository
git init Leeres Git-Repository in ~/gitprojekte/erste-schritte/.git/ initialisiert
.git unser Repository
gitprojekte
└── erste-schritte
├── .git Hier legt Git die Historie des Projektes ab.
Das erste Commit
git add bar.txt foo.txt git commit --message "init" add-Befehl bestimmt welche Dateien in das nächste Commit aufgenommen werden
Unsere Dateien
Das erste Commit
[master (Basis-Commit) 6cc5776 ] init
2 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 bar.txt
create mode 100644 foo.txt
Branch
Hashwert
Commit Message
Status
rm -f bar.txt
touch bar.html
vi foo.txt
Status abfragen
git status Auf Branch master
Änderungen, die nicht zum Commit vorgemerkt sind:
(benutzen Sie "git add/rm < Datei>...", um die Änderungen zum Commit vorzumerken)
(benutzen Sie "git checkout -- < Datei>...", um die Änderungen im Arbeitsverzeichnis zu verwerfen)
gelöscht: bar.txt
geändert: foo.txt
Unversionierte Dateien:
(benutzen Sie "git add < Datei>...", um die Änderungen zum Commit vorzumerken)
bar.html
keine Änderungen zum Commit vorgemerkt (benutzen Sie "git add" und/oder "git commit -a")
Status
git diff foo.txt
diff --git a/foo.txt b/foo.txt
index e69de29..345e6ae 100644
--- a/foo.txt
+++ b/foo.txt
@@ -0,0 +1 @@
+Test
Mit Q kommt ihr wieder raus.
Paradox git add
git add foo.txt bar.html bar.txt Egal ob
eine Datei bearbeitet, hinzugefügt oder gelöscht wurde, mit dem add-
Befehl bestimmt man, dass die Änderung übernommen werden soll.
Status abfragen
git status
Auf Branch master
Zum Commit vorgemerkte Änderungen:
(benutzen Sie "git reset HEAD < Datei>..." zum Entfernen aus der Staging-Area)
neue Datei: bar.html
gelöscht: bar.txt
geändert: foo.txt
Das zweite Commit
git commit --message "Einiges geändert."
[master a7f3ece] Einiges geändert.
3 files changed, 2 insertions(+), 2 deletions(-)
create mode 100644 bar.html
delete mode 100644 bar.txt
Historie betrachten
git log
commit a7f3ece79d5f38a13f64355bb195f5c5861e3747 (HEAD -> master)
Author: Niels Nübel < niels@kicktemp.com>
Date: Wed Mar 27 11:25:25 2019 +0100
Einiges geändert.
commit 6cc5776005924cc841955333169831cb95af3d1f
Author: Niels Nübel < niels@kicktemp.com>
Date: Wed Mar 27 11:20:20 2019 +0100
init
Der log-Befehl zeigt die Historie des Projekts. Die Commits sind chronologisch
absteigend sortiert.
Zusammenarbeit mit Git
eigenen Workspace
eigenes Repository
Repository
Repository klonen
cd ..
git clone erste-schritte erste-schritte-klon Klone nach 'erste-schritte-klon' ...
Fertig.
clone-Befehl bestimmt welche Dateien in das nächste Commit aufgenommen werden
Quelle
Ziel
Verzeichnis
gitprojekte
├── erste-schritte-klon
│ ├── .git
│ ├── bar.html
│ └── foo.txt
└── erste-schritte
├── .git
├── bar.html
└── foo.txt
Ändert die Datei erste-schritte/foo.txt.
cd /projekte/erste-schritte
vi foo.txt
git add foo.txt
git commit --message "Eine Änderung im Original."
History Kompakt
git log -oneline
fc59790 (HEAD -> master) Eine Änderung im Original.
a7f3ece Einiges geändert.
6cc5776 init
Ändert im nächsten Schritt die Datei erste-schritte-klon/bar.html
im Klon-Repository
cd /projekte/erste-schritte-klon
vi bar.html
git add bar.html
git commit --message "Eine Änderung im Klon."
History im Klon
git log -oneline
9b29e5c (HEAD -> master) Eine Änderung im Klon.
a7f3ece (origin/master, origin/HEAD) Einiges geändert.
6cc5776 init
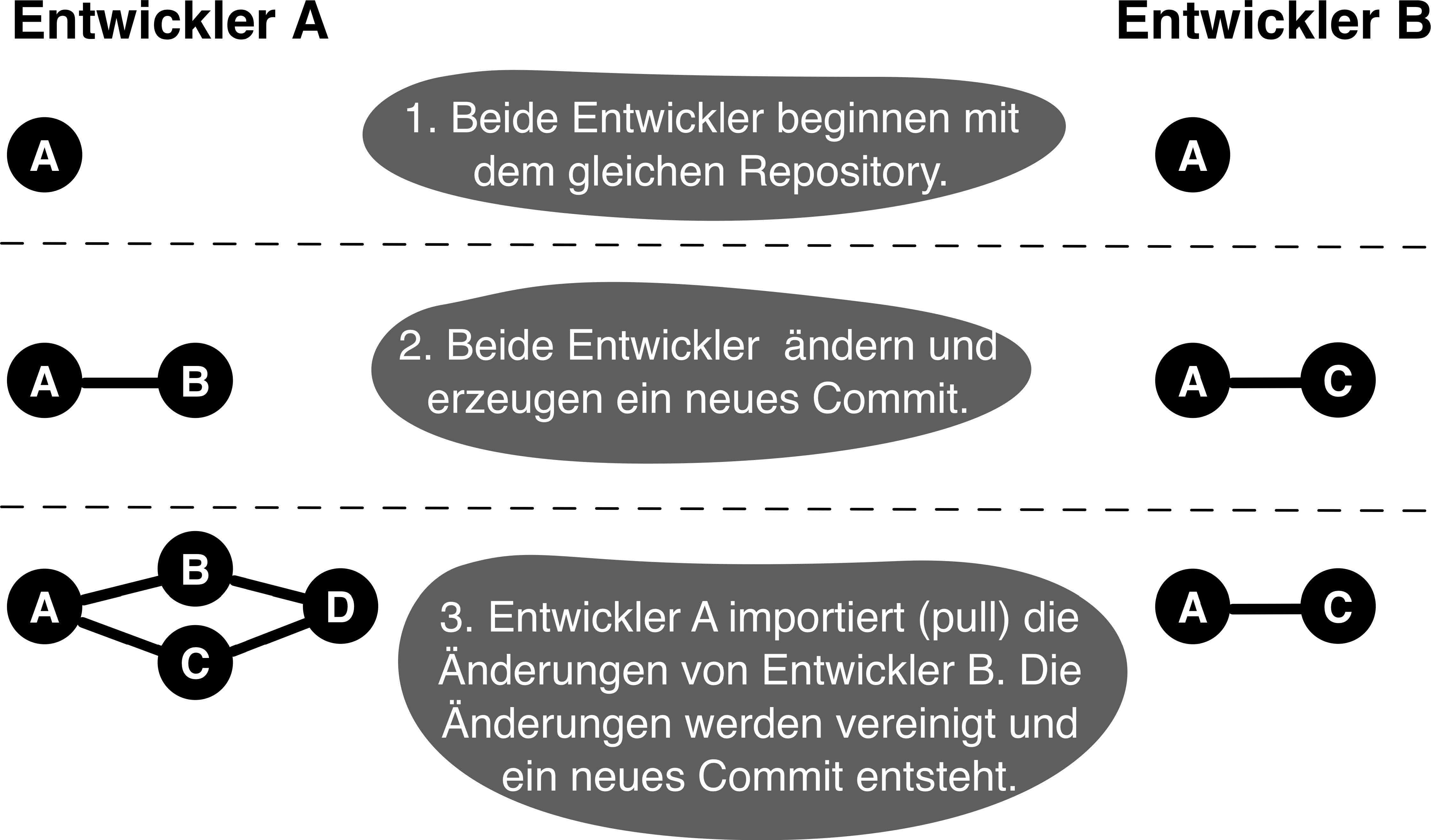
Wir haben jetzt in jedem Repo zwei gemeinsame Commits und jeweils ein neues Commit. Wir wollen jetzt das neue Commit aus dem Original in den Klon übertragen.
pull-Befehl
cd /projekte/erste-schritte-klon
git pull
remote: Objekte aufzählen: 5, Fertig.
remote: Zähle Objekte: 100% (5/5), Fertig.
remote: Komprimiere Objekte: 100% (2/2), Fertig.
remote: Gesamt 3 (Delta 0), Wiederverwendet 0 (Delta 0)
Entpacke Objekte: 100% (3/3), Fertig.
Von /Users/niels/Development/kicktemp/gitprojekte/erste-schritte
a7f3ece..fc59790 master -> origin/master
Merge made by the 'recursive' strategy.
foo.txt | 1 +
1 file changed, 1 insertion(+)
git log --graph --oneline
* 5ab262c (HEAD -> master) Merge branch 'master' of /Users/niels/Development/kicktemp/gitprojekte/erste-schritte
|\
| * fc59790 (origin/master, origin/HEAD) Eine Änderung im Original.
* | 9b29e5c Eine Änderung im Klon.
|/
* a7f3ece Einiges geändert.
* 6cc5776 init